- Redis
- 什么是Redis、使用场景有哪些
- Redis 为什么这么快?
- Redis 数据类型及使用场景
- 五种常见的 Redis 数据类型是怎么实现?
- Redis是单线程吗
- Redis 采用单线程为什么还这么快?
- Redis 如何实现数据不丢失?
- Redis 如何实现服务高可用?
- 集群脑裂导致数据丢失怎么办?
- Redis 使用的过期删除策略是什么?
- Redis 持久化时,对过期键会如何处理的?
- Redis 主从模式中,对过期键会如何处理?
- Redis 内存满了,会发生什么?
- 什么是Redis 内存淘汰策略
- Redis 内存淘汰策略有几种
- LRU 算法和 LFU 算法有什么区别?
- 如何避免缓存穿透、缓存击穿、缓存雪崩?
- 如何设计一个缓存策略,可以动态缓存热点数据呢?
- 常见的缓存更新策略?
- 如何保证缓存和数据库数据的一致性?
- Redis 如何实现延迟队列?
- Big Key问题
- 大量数据要导入Redis该怎么办
- Redis 事务支持回滚吗?
Redis
什么是Redis、使用场景有哪些
答:
-
Redis:Redis是一种基于内存的数据存储,因为它基于内存所以读写速度非常快。而且Redis的命令执行是单线程的,不会存在并发安全问题。 -
Redis可以用来
数据缓存、分布式锁、消息队列等场景。
Redis 为什么这么快?
答:
- Redis 基于
内存,内存的访问速度比磁盘快很多; - Redis 是
单线程事件循环和IO 多路复用 - Redis 内置了多种
优化过后的数据类型,性能非常高。 - Redis
通信协议实现简单且解析高效。
Redis 数据类型及使用场景
答:
- 5 种基础数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- 4 种特殊数据类型:HyperLogLog(基数统计)、Bitmap (位图)、GEO (地理位置)、Stream。
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 无法避免消息丢失;2. 一条消息无法被多个消费者一起消费)等。
- Hash 类型:缓存对象(用于对象属性需要经常进行修改的)、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞(例如一个用户只能点一次赞)、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数(一天内用户的多次访问只算一次)等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
五种常见的 Redis 数据类型是怎么实现?
答:
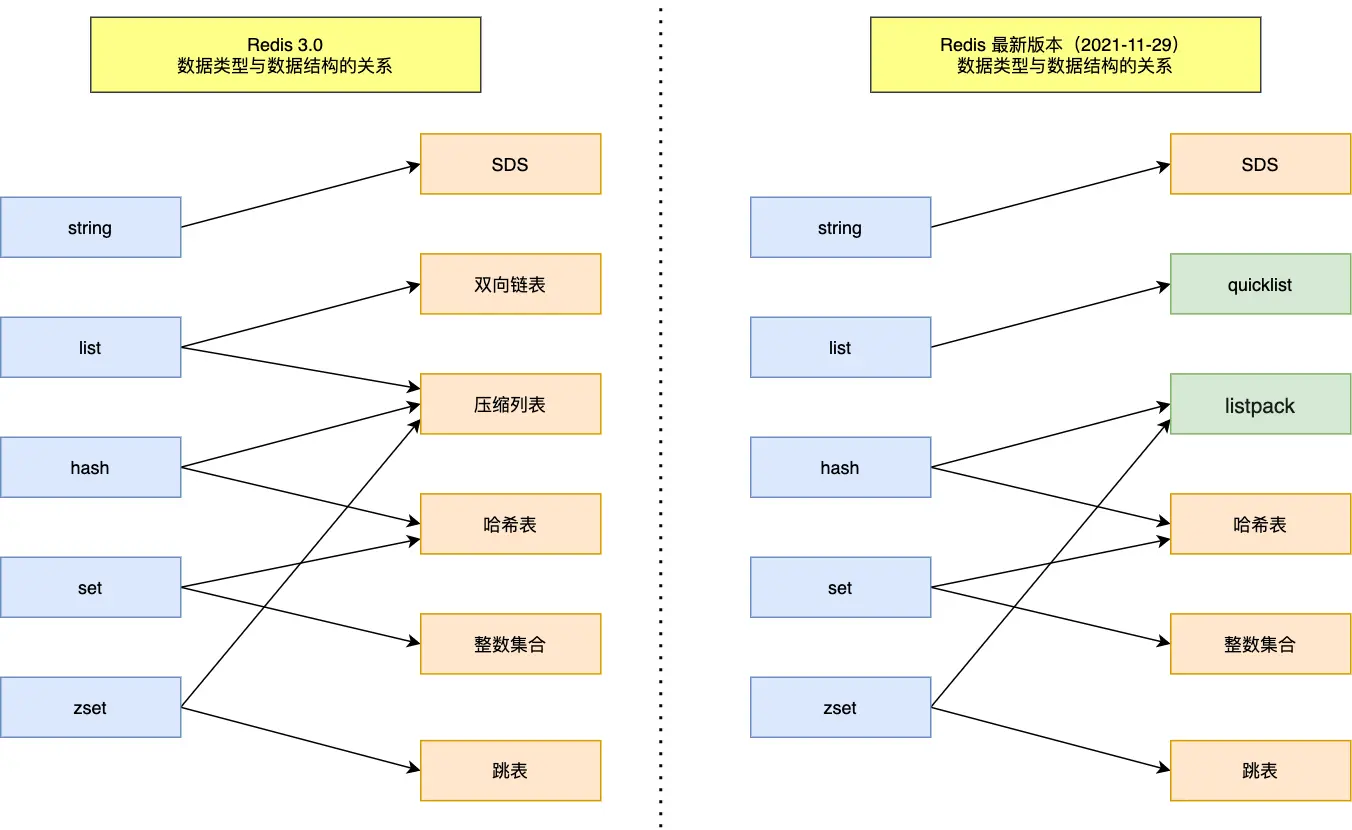
1、String 类型内部实现
- Redis的字符串用的并不是原生C语言的字符串,用的是一个结构体SDS(简单动态字符串),
- SDS相比于原生C语言的字符串,1. 他是二进制安全的(C语言的字符串底层是一个字符数组,并且使用了一个结束标识符)2. SDS的结构体维护了一个当前字符串的长度,相比于C语言,它的时间复杂度是O(1)。3. SDS实现了内存的扩充。
- String有3种编码方式:
raw、embstr、int raw:基于简单动态字符串(SDS)实现,存储上限为512mb。RedisObject使用一个指针指向的SDSembstr:分配的头信息和SDS是一块连续的内存空间。根据SDS存储的字节大小会将raw转为embstrint:如果字符串存储的是整数值,并且是在8个字节以内,则会采用int编码。会直接将值存放到ptr属性的位置。
2、Hash 类型内部实现
- Hash结构默认采用
ZipList编码。因为ZipList不是键值存储,所以使用相邻的两个entry分别保存field和value - 当数据量较大时,则会转为Dict编码。
3、List 类型内部实现
- 在
3.2版本之前,Redis采用ZipList或LinkedList来实现List,当元素数量少的时候采用ZipList编码,多的时候用LinkedList编码。 - 在
3.2版本之后,Redis统一采用QuickList来实现List
4、Set 类型内部实现
- 采用
Dict编码,Dict中的key用来存储元素,value统一为null。 - 当存储的数据都是整数,并且元素数据较少时,采用的时
IntSet编码(一块连续的内存空间)。
5、ZSet 类型内部实现
ZSet底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。
Dict + SkipList。Dict 保证键值存储、键必须唯一,SkipList保证可排序。缺点:Dict里面存储一份数据,SkipList中也需要存储一份数据。非常消耗内存。- 果存储的数据量比较少时,采用
zipList。为了保证ZSet的需求- 使用连续的两个entry来记录element和score。
- 并按score值升序进行排列。
Redis是单线程吗
答:
- Redis的命令处理是单线程执行的。
- 在Redis 6.0
网络IO处理采用了多线程执行。 - Redis在启动的时候,也会启动后台线程(BIO)的。这些后台线程会去执行一些比较耗时的操作。例如数据持久化等。
Redis 采用单线程为什么还这么快?
答:
- Redis本身就是基于内存操作,执行速度非常快,它的性能瓶颈是网络延迟,而不是执行速度。
- Redis 采用单线程模型可以避免多线程之间的竞争。多线程还要考虑线程安全问题,实现复杂度也会大大增多。
Redis 如何实现数据不丢失?
答:
- 为了保证内存数据的不丢失,Redis实现了持久化机制。
有2种持久化的方式:
- RDB持久化
- AOF持久化
1、RDB持久化
RDB持久化是什么: 简单来说就是把内存中的所有数据都记录到磁盘RDB文件中。
什么时候执行RDB:在三种情况下RDB会被执行:
- 执行
save命令:主进程去执行RDB,其他命令会被阻塞。 - 执行
bgsave命令:开启一个子进程去执行RDB,主进程不会受影响。 Redis停机时:Redis停机时会执行一次save命令,实现RDB持久化。
RDB执行原理:
- 当
bgsave执行时,主进程会 fork 创建一个子进程。子进程和主进程共享同一块内存区域。 - 子进程负责将内存中的数据写入到RDB文件,主进程还可以继续进行工作。主要依靠的是
copy-on-write技术。- 当主进程执行读操作时,与往常一样,直接访问内存中的数据即可。
- 当主进程执行写操作时,会在内存中拷贝一份要修改的数据,对拷贝的数据执行写操作,这样不会影响到子进程读取的内存数据。
2、AOF持久化
AOF持久化是什么: 把Redis每一条写操作命令记录在AOF文件中。
什么时候执行AOF:有3种刷盘时机
- always:每执行一次写命令,立即记录到AOF文件
- everysec:每隔1秒写到AOF文件。
- no:写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
RDB持久化缺点: RDB恢复数据快,但是最后一次快照之后的数据可能会丢失。
AOF持久化缺点: AOF数据安全性更好,但是恢复数据时需要执行每条命令,恢复速度慢。
在很多场景下,通常是结合使用RDB和AOF。
Redis 如何实现服务高可用?
答:
要想设计一个高可用的 Redis 服务,要从 Redis 的多服务节点来考虑,比如 Redis 的主从集群、哨兵模式、分片集群。
1、主从集群
为什么需要主从集群:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
介绍主从集群:主节点负责写操作,从服务器负责读操作。主节点会把信息同步给从节点,保证数据的一致性。
有两种同步方式:
- 全量同步:主从第一次同步是全量同步,主节点会将完整数据生成的RDB发给从节点。从节点加载RDB文件的数据。
- 增量同步:从节点会提交自己的offset给主节点,主节点会把log文件中从offset之后的操作命令发给从节点。从节点执行命令进行同步。
2、哨兵模式
为什么需要哨兵模式:为了保证主从集群能够进行自动故障恢复。
哨兵监控原理:
- 哨兵每隔1s向集群的每个实例发送
ping命令 - 如果有实例未在规定的时间响应,则认为该实例主观下线
- 如果超过指定数量的哨兵都认为该实例主观下线了,则该实例客观下线。
集群故障恢复原理
- 主节点发生故障后,哨兵会从从节点中的选出一个作为主节点。
- 挑选一个延迟最小、优先级最高且数据最完整的节点来晋升为新的主节点
3、分片集群
主从集群和哨兵模式解决了高并发读、高可用的问题。
分片集群解决的是:海量数据存储和高并发写的问题。
分片集群中有多个主节点,每个主节点保存不同的数据。主节点与主节点通过ping命令检测健康状态。
每个主节点都有自己的从节点。
集群脑裂导致数据丢失怎么办?
答:
- 修改配置文件的配置,禁止主节点进行写数据,直接把错误返回给客户端。
Redis 使用的过期删除策略是什么?
答:
有两种过期删除策略:
- 惰性删除
- TTL到期后不会立刻删除,而是在访问一个key的时候,先检查该key的存活时间,如果已经过期才执行删除。
- 缺点:如果一个key过期了,只要这个key一直未被访问,则会一直存留在内存中。
- 周期删除
- 每隔一段时间,随机的挑选部分过期的key,然后执行删除。
- 缺点:过期键可能不会立即被删除,每次随机选择一部分的key检查。难以确定删除操作的频率。如果执行的太频繁,就会对 CPU 不友好;如果执行的太少,过期键不会立即被删除。
Redis 持久化时,对过期键会如何处理的?
答:
- RDB持久化:在写入RDB文件之前,会先对key进行过期检查,过期的key不会被写入到RDB文件中。
- AOF持久化:如果某个key还未过期,则记录此key。当某个key过期被删除了,则会在AOF文件的末尾添加一条删除命令。
Redis 主从模式中,对过期键会如何处理?
答:
- Redis主从模式中,对过期键的处理主要由主节点负责,主节点删除过期键后,会发出删除命令通知从节点。
Redis 内存满了,会发生什么?
答:
- 在 Redis 的运行内存达到了某个阀值,就会触发内存淘汰机制,这个阀值就是我们设置的最大运行内存,此值在 Redis 的配置文件中可以找到,配置项为
maxmemory。
什么是Redis 内存淘汰策略
答:
- 内存淘汰策略:就是当Redis内存使用达到设置的阈值时,Redis主动挑选部分key删除以释放更多内存的流程。
- Redis是在什么时候检查内存的: 在任何的命令执行之前,都要做内存检查。
Redis 内存淘汰策略有几种
答:
Redis支持8种不同策略来选择要删除的key:
noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。volatile-ttl::对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
allkeys-random:对全体key,随机进行淘汰。也就是直接从db->dict中随机挑选volatile-random:对设置了TTL的key,随机进行淘汰。也就是从db->expires中随机挑选。
allkeys-lru:对全体key,基于LRU算法进行淘汰volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
allkeys-lfu:对全体key,基于LFU算法进行淘汰volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
LRU 算法和 LFU 算法有什么区别?
答:
- LRU:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU:最少频率使用。会统计每个ky的访问频率,值越小淘汰优先级越高。
Redis如何实现的LRU和LFU:

LRU:在 Redis 的对象结构体中添加一个字段,用于记录此数据的最后一次访问时间。
LFU:同样也是使用LRU的字段进行记录,统计的并不是真实的访问次数,而是通过计算得到的逻辑访问次数。

如何避免缓存穿透、缓存击穿、缓存雪崩?
答:
- 缓存穿透:请求的数据缓存和数据库中都不存在
- 缓存空值
- 使用布隆过滤器
- 缓存击穿:缓存中热点数据过期了,大量请求直接访问到了数据库。
- 互斥锁:只让一个业务线程重建缓存。其他线程等待锁的释放,然后重新查询缓存,要么直接返回空值。
- 缓存雪崩:大量缓存数据在同一时间失效,大量请求直接访问到了数据库。
- 不同key的失效时间添加随机值
- 不设置缓存的过期时间
如何设计一个缓存策略,可以动态缓存热点数据呢?
答:
热点数据动态缓存的策略总体思路:通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据。
比如需要缓存用户经常访问的Top 1000商品。
- 设置一个Zset集合,容量大小为1000,score为当前商品访问的时间,element为商品id。
- 用户查询一个商品的信息时,首先查询缓存中Zset集合是否存在,第一次是不存在。如果存在,则再根据id去另一个缓存结构中查询信息。
- 查询数据库获取信息。之后判断缓存中Zset集合大小是否达到1000,如果没有达到,则将该商品id和访问时间设置到Zset集合中。并将商品的信息缓存到另一个缓存结构中。如果达到了1000,则删除Zset中排名第一个的元素(Zset中访问时间按升序排序),然后将该商品信息放入Zset中。
常见的缓存更新策略?
答:
- 写操作
- 先更新数据库、删除缓存
- 读操作
- 先查询缓存,缓存命中直接返回
- 缓存未命中,查询数据库,写入缓存
如何保证缓存和数据库数据的一致性?
答:
- 写操作时
- 先更新数据库、删除缓存。(但再并发情况下,有可能出现数据不一致)

改进
- 方案一(防止被其他重写):延时双删。先更新数据库,然后删除缓存,稍后再删除一次缓存。
- 方案二(防止删除时失败):重试机制。可以把要删除缓存的数据放到消息队列,如果删除成功则从消息队列移除。否则重试。
Redis 如何实现延迟队列?
答:
- 可以使用Zset集合实现。score为
当前时间+要延迟的时间。 - 通过
zadd向集合中添加消息 - 再利用
zrangebysocre key min max命令(min:0,max:当前时间),循环查询符合相应时间的消息,然后进行业务处理。
Big Key问题
答:
什么是Big Key
- Bigkey通常指的是某个Key所占的内存较大、或者是某个Key中成员数量较多。这样的Key叫做BigKey
- 推荐值:单个Key的value小于
10KB,对于集合类型的key,建议元素数量小于1000
Big Key的危害
- 客户端阻塞: Redis执行命令是单线程处理的,如果操作一个BigKey比较耗时,则会阻塞客户端。
- 工作线程阻塞: 对元素较多的hash、list、Zset做运算运算时,会使工作线程被阻塞。
- CPU压力: 对BigKey的数据序列化和反序列化会导致CPU的使用率飙升。
如何发现Big Key
- 使用
redis-cli --bigkeys命令查找Bigkey。缺点:该命令只能返回每种类型中最大的那个 bigkey,对于集合类型,它返回的是个数最多的,而不是占用内存最多的。 - 利用
scan命令可以自己编写程序扫描,scan每次都是扫描的一部分(相对于扫描全部的key,对线程还友好一点),并且返回下一次的游标位置。
如何删除Big Key
- Redis 4.0以上,可以使用异步线程删除:
unlink命令 - Redis 4.0之前,对于集合类型,可以分批次的删除集合元素,并且Redis也提供了集合扫描的命令:
hscan、zscan,分批次的删除扫描到的元素。
大量数据要导入Redis该怎么办
答:
大量数据导入时的主要耗时是在:网络传输耗时
命令批处理方案:
- 原生的
M操作。例如:mset、hmset实现批量插入- M操作是原子操作。中间不会穿插其他的操作。
- MSET虽然可以批处理,但是却只能操作部分数据类型(String、hash)
Pipeline命令。Pipeline可以执行各种的数据类型的命令,因此如果有对复杂数据类型的批处理需要,建议使用Pipeline功能。- Pipeline的多个命令之间不具备原子性
Redis 事务支持回滚吗?
答:
- Redis 的事务可以确保一系列命令的原子性执行,但它并不支持事务回滚。也就是某个命令在执行过程中出错,那么后面的命令仍然会被继续执行。
MULTI开启事务,EXEC执行事务,DISCARD取消事务(没有回滚作用)